Physics 50
Module 1
Harvey Mudd College
Week 3: Generating Data to Test a Hypothesis
This week we are going to generate a data set to test our hypothesis. This will include more detailed data collection for analysis than the exploratory measurement from Weeks 1-2.
Review: Estimating Uncertainties
Reporting Data with Significant Figures
Background Reading and Miniquestions
At the end of this week you should have a complete data set for the measured critical angle for (at least) five different masses.
Before you begin taking data, there are two principles that we would like to introduce: “real-time data visualization” and “iterative experimental design”. In taking experimental data, we don’t want to just blindly follow the procedure laid out in the experimental design. We need to ensure the data we are taking is reasonable and that our conclusions are well-founded and impactful. One way to ensure the data is reasonable is to have some real-time visualization set up (“plotting as you go”). That way we can see our data as we are taking it, and adapt based on any new information.
Warning When “plotting as we go” we don’t want to make a real-time decision that incorrectly shapes our conclusions. For example, suppose we had made a plan to take 10 data points based on our exploratory measurements. But in taking the first 3 data points we notice a small sample standard deviation and that if we just stop taking data now, we end up with a reasonable conclusion. If we stop our hypothesis testing based on whether or not the data gives us the answer we are looking for, then we might draw INCORRECT conclusions based on the spread of just a few data points explained here. If this puzzles you, you might look back to the discussion of random uncertainty. Related concerns are also raised here.
To provide some separation between our experimental decisions and our hypothesis testing, we will iterate on our experimental design. It’s okay to change your plan if it turned out to be a bad one. But we want to provide some justification for any changes we make to our initial plan. Here we will provide more details about the two principles we will employ this week, “real-time data visualization” and “iterative experimental design”. We encourage you to refer back to them as you undertake your detailed data collection.
Real-time Data Visualization
An important habit we would like you to develop as an experimentalist is to be plotting/visualizing your data as you take it. Even though you made a plan with your experimental design, there are many unexpected things that can happen. You should set up your data collection (e.g. in Google Sheets) so that recording each data point automatically updates a plot with your data and calculates statistical quantities (sample mean, sample standard deviation, and standard error of the mean). Here are some things to keep an eye out for as your taking your data:
- Is your sample mean very different than what you measured in your exploratory analysis?
- If so, then try to troubleshoot what the differences might be (e.g. a calculation error, an uncontrolled variable), and then revise your approach
- Is your sample standard deviation much larger than what you found in your week 2 exploratory analysis?
- If so, then maybe you need to revise how many data points you plan on taking
- Does your data look Normally-Distributed* (like a Gaussian, bell-curve)?
- If not, then you should try to investigate uncontrolled variables or perhaps increase the number data points of your experimental design
*Note: if you have taken only a few data points, you shouldn’t expect your data to look like it’s Normally-Distributed, even if it was being sampled from a Normal distribution. Make sure you take enough data before checking if it’s Normally-Distributed
Miniquestion: Making an experimental plan
Click here to open in a new tab
Practical Considerations to the Experimental Design
Before delving deeply into data collection it is helpul to take a step back and consider whether your experimental plan is practical. In this case, will you be able to complete the data collection in the time that should be allocated to a 1-unit class or is your plan unrealistic. An example of a practical consideration is in the randomization of the mass.
Perhaps a concrete example would be helpful. Imagine your mass is a container for which you are changing the mass by filling it with water. If you fully randomize the experiment the way we suggested last week you will have to add or remove water for each of the 25 measurements. Because there is significant start up time in terms of accurately measuring a consistent amount of water, this will take significantly longer than collecting all of the data for a single mass and then moving on to the next data point. You might make a conscious choice not to fully randomize the experiment. However, you should at a minimum randomize those parameters which can be reasonably randomized within the time constraints of the experiment. In this case this might mean choosing not to randomize every single trial but randomizing the trials in batches. A batch might include collecting all of the data for a given mass at once or as a compromise collecting 2-3 data points each time you set up the experiment with a given mass. The order in which you work through the “batches” should still be randomized. However, if instead of adding water you are adding crayons, it might not significantly affect the required time to complete the experiment to fully randomize the trials in which case this would be preferable.
Side note: we do not expect you to have access to a scale at home, can you think of an alternative way to estimate the mass in the previous experiment without one? Depending on your experimental configuration you may or may not be able to make a good estimate of the mass, when it comes to presenting your data it is okay to use alternative units. e.g. if you are adding more crayons to a pencil case but do not know the mass of each crayon you might report your results in terms of the number of crayons added.
Iterative Experimental Design
If your real-time data visualization indicates something is going wrong, you should iterate on your experimental design. Sometimes this is just as simple as making a note in your lab notebook of the revised plan. For example, “The first 5 data points had a sample standard deviation larger than what was observed in the exploratory measurement. Instead of 5 data points, I will now take 10.”
Or maybe you’ve noticed some uncontrolled factor in your experiment and you need to start over. In that case, carefully note any data that was taken, but do not delete it! Even if you aren’t going to include data you’ve taken in your analysis, it’s important to keep a record of what happened. Here’s an example of how you might document such an event in your lab notebook: “My experimental design called for 5 data points, but in my first 3 data points I noticed a larger standard deviation than I expected based on my exploratory measurements. I noticed that the pencils inside my hard pencil case (used as the block) were sometimes shifting inside the pencil case before the pencil case was slipping on my book (the ramp). The first 3 trials were taken without carefully controlling that factor, and I will not include them in my analysis. In subsequent trials, I will make sure the pencils are pushed up against the “downhill” side of the pencil case before starting. I will take 5 new data points according to my experimental design.”
Often even if things go as planned and we finish taking data according to our experimental design, we can end up with an inconclusive or unclear result. Just because you complete your experimental design, doesn’t mean you are done with your experiment! It’s far easier to communicate your results when there is a clear conclusion. It’s often worth the effort to revise your plan and take more data, which will save you time trying to communicate your results (which we will do in Week 4) and allow you to reach a stronger conclusion.
As an experimentalist, you have to make the tough decision of when the experiment is complete. It takes years of experience to build up the knowledge and intuition to comfortably decide “when am I done?”. Even collaborators in the same research group can disagree on this point. To help get you started, let’s look at a few examples in the following miniquestion.
Miniquestion: Iterative Experimental Design
Click here to open in a new tab
Reporting Data with Significant Figures
Something to consider when communicating your results is the number of significant figures (decimal places) you report. Imagine you calculated the coefficient of static friction and its uncertainty. The value you obtain from Google Sheets is 0.44030407 ± 0.00403726. So you should communicate this value when you write up your experimental results, right? Hold on: do you really know the value of \(\mu\) to the 8th decimal place? Our uncertainty of \(\delta \mu_s =\)0.00403726 tells us that we are unsure of the 3rd decimal place, so we are definitely not sure about the value in the 8th decimal place of \(\mu_s =\)0.44030407! This digit is insignificant; you don’t truly have that kind of precision in this experiment and cannot quote results that would imply otherwise.
This is where the term significant digits, or “sig figs” for short, comes into play. We only want to report digits that are significant — accurately reflect the precision of our experiment — in our results. We will now present the rule of thumb for determining significant digits:
-
Round and keep only one digit in your uncertainty
- in our example this would mean we report our uncertainty as \(\delta \mu_s = 0.004\)
Exception: if the most significant digit — in our example above, the digit in red 0.00403726 — is a 1 or 2, then report two digits in the uncertainty. For example: if your uncertainty is 0.0237304 then its most significant digit is a 2 so we will keep two digits, resulting in an uncertainty of 0.024 after rounding.
-
Round your measured value so the placement of the least significant digit matches that of the rounded uncertainty. Wow, that sounds confusing so let’s see how this applies to our example above:
- in our example we began with 0.44030407 ± 0.00403726. We determined that the uncertainty should be 0.004, meaning the least significant digit of the uncertainty is in the 3rd decimal place. We need to round our measurement value to the same digit so the value we will report for our measurement is 0.440 ± 0.004.
Miniquestion: Reporting Significant Figures
Click here to open in a new tab
Review of Uncertainty Estimation
Before collecting and analyzing your data this week, please make sure that you have read this discussion about combining uncertainties
And if you’re confused about the rounding of the values, you might want to read this first
To make sure you’ve understood these ideas, please complete the following mini-question. This is going to come up repeatedly throughout the course. If you have any uncertainty about your response please stop by office hours and talk to us or consult with your classmates through Piazza.
Miniquestion: Combining Random and Resolution Uncertainty
Click here to open in a new tab
Week 3 - Generating Data to Test a Hypothesis
Data Collection
With the background reading complete, you are now ready to start the data collection process.
Step 1: Set-up a Spreadsheet
Your spreadsheet should allow you to:
- Record data.
- Plot your data in real time.
- Analyze your data. In this case your goal is to determine the co-efficient of static friction for each mass.
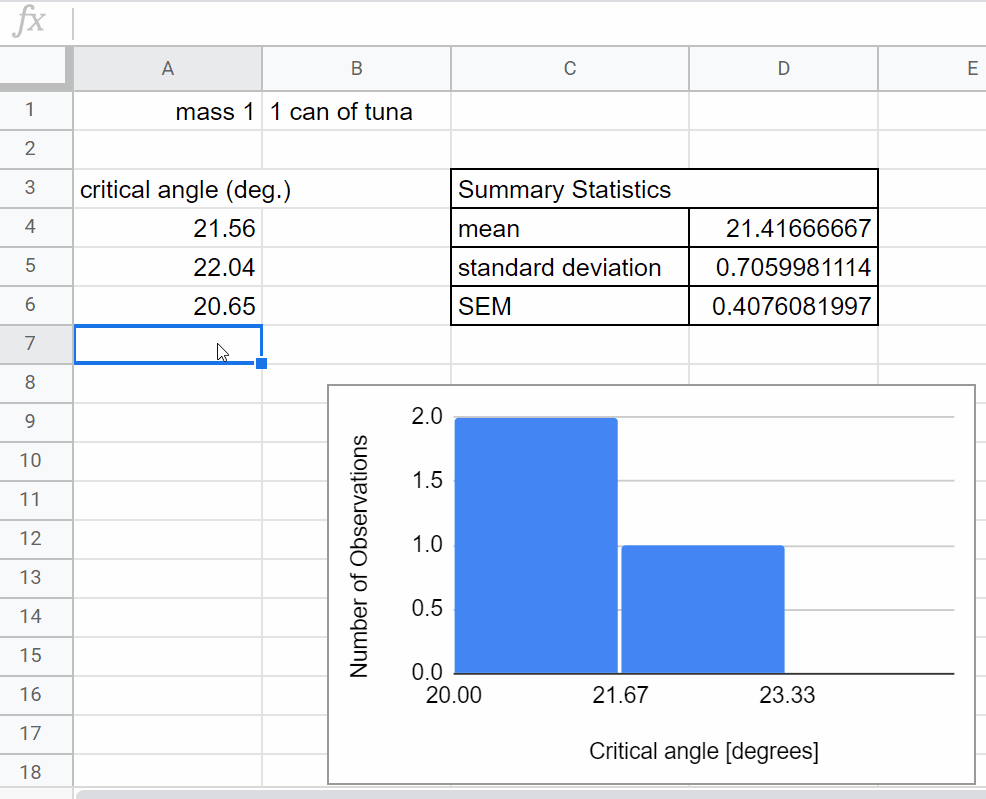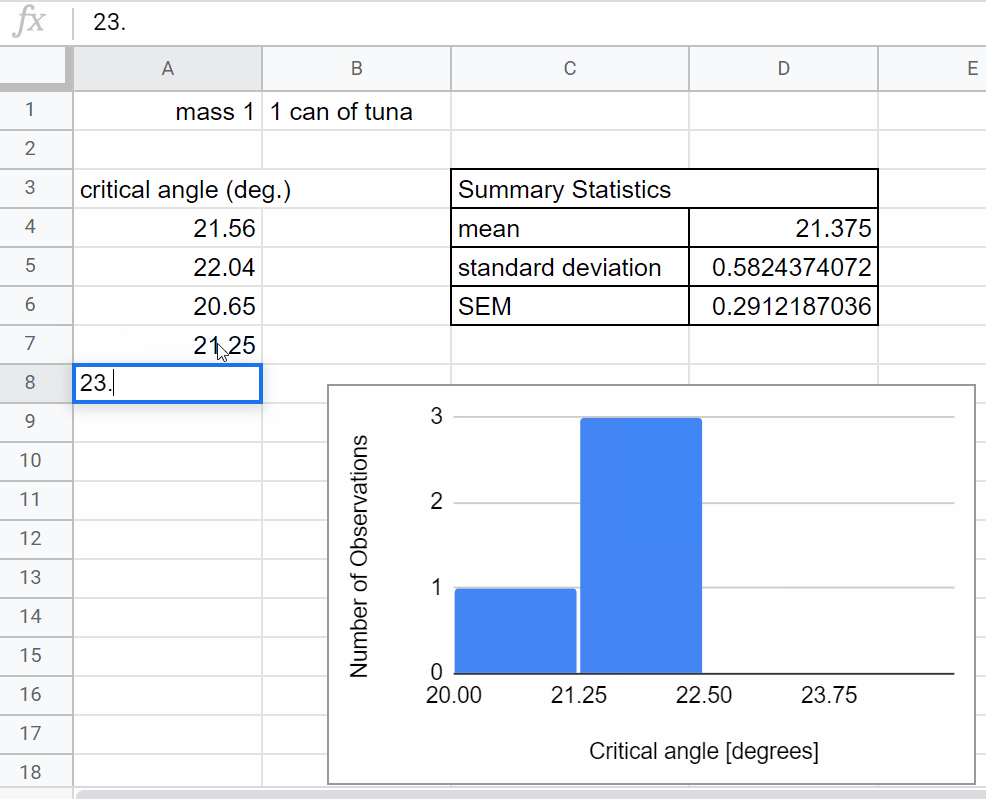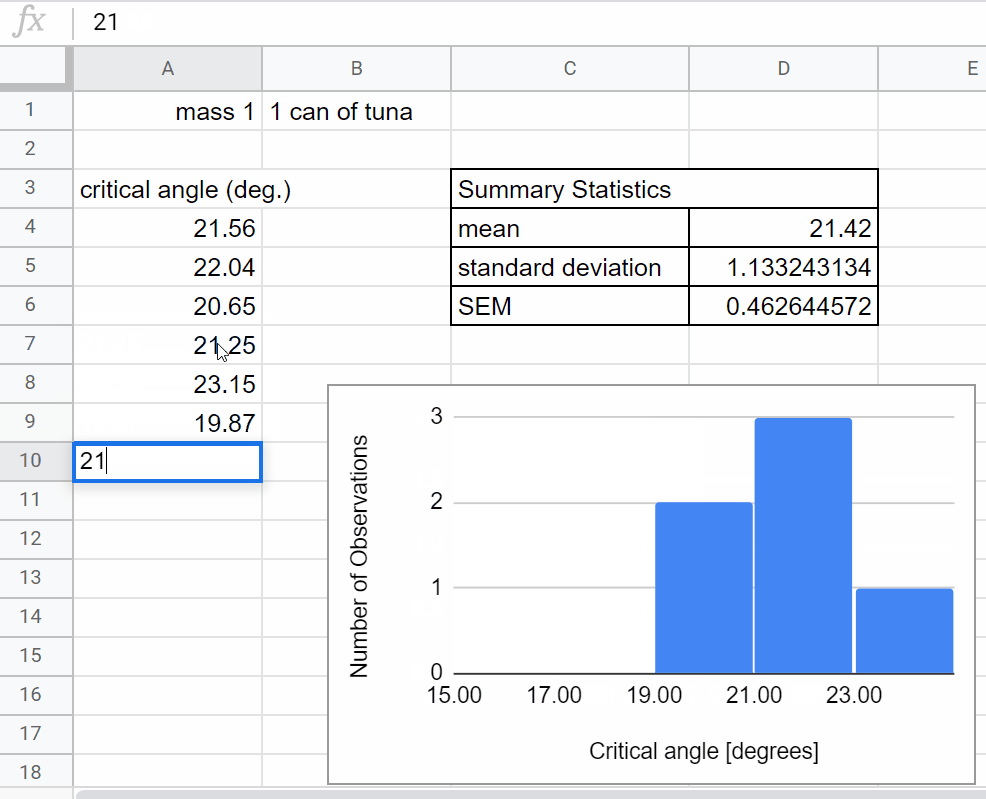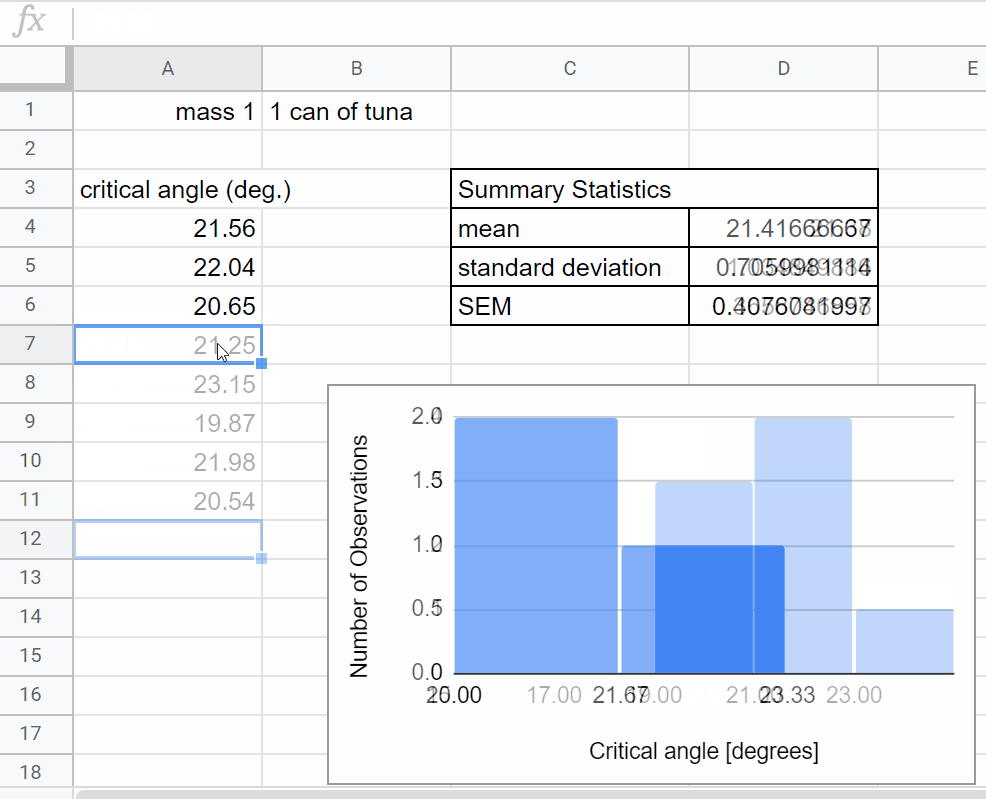
Look back to the spreadsheet you used for your preliminary data collection last week. You will want to organize your data collection in a similar way.
Click here for detailed steps to guide you through the process of setting up your spreadsheet
These steps will guide you through this process:
- Begin by creating a worksheet. This can be a new sheet in your existing worksheet using the add sheet button in the bottom left or a new worksheet.
-
Set up a table to determine the critical angle for the first mass.
-
Give the table a title.
-
Title the column you will be using for data collection (\(\theta_c\))
-
As part of the Experimental Design you prepared for the week #2 checkpoint you estimated a reasonable number of data points to achieve the desired accuracy. Use this as a guide for how many rows to include in your table.
-
Use the borders feature to outline the table.
-
-
Set up a graph to plot your data in real time. For this experiment you will want to plot a histogram of your measurements of the the critical angle \(\theta_c\). Today we are setting up an informal plot to look at our data in real time. This is different from a more formal figure that you would use to share/communicate your results - creating formal figures is a more careful process, we will do that next week after we’ve collected and reflected on our data. Here we summarize how to create a histogram in sheets. You can find more helpful information at: Click here to open in a new tab
-
You can add a chart by selecting “insert” and then “chart” from the drop down menus.
-
A new “Chart Editor” Menu will appear on the RHS of the screen. Use the drop down menu under chart type to select “histogram”.
-
On the next line of the “Chart Editor” set data range to be the cells in which you plan to insert your data (you may have to go back and edit this later if you collect more data than expected)
-
Press the x in the top right to exit the chart editor.
-
Click on your chart and move it to a convenient spot in your worksheet. You will want to customize the chart further once you begin collecting data.
-
-
Now add a row to calculate the average value for the critical angle, \(\theta_c\) and standard error. This will be analogous to what you did last week just with more data, go ahead and look back to last week’s worksheet to set-up the calculations.
-
Add another row to use the same calculations you did last week to calculate the coefficient of static friction, \(\mu_s\), for your new data set.
- Now you need to set up your worksheet to collect data for the second mass. There are two ways you might go about this. One is to add a second column to the right of your first column, duplicating the equations for your calculations. You should then create a second histogram to monitor the data from the second mass in real time. Alternatively, you can duplicate the sheet. At the bottom left are tabs that allow you to have multiple sheets in your worksheet. If you click on the downward arrow next to your sheet name a menu will appear. Click on “duplicate” and you will now have a second identical sheet ready for data from your second mass. You can rename your sheets from the same menu.
Once you have collected a few data points you will want to go back to the chart editor and select customize. Next week we will focus on polishing our plot for communicating our results but even for your own records you want to make a few adjustments while collecting data.
-
Use the Chart and axis title dropdown to add a chart title
-
Within the same dropdown menu, if you click on chart title you can change the dropdown to “Horizontal axis title”. Go ahead and label your axis.
-
The histogram dropdown will allow you to change the bucket size (by default it will be on auto which you may or may not find satisfactory depending on your data)
Step 2: Collect and analyze data
Make sure to record all relevant details such as what mass you are using. Always include units when recording data. If you are switching back and forth between the masses to randomize your experiment, then be very careful about where in your spreadsheet you are recording your data.
As you collect data, be on the lookout for problems like those mentioned in the Real-time Data Visualization section above. The histogram and summary statistics of your critical angle will help you identify if you need to adjust your plan.
Step 3: Reflect and Iterate
It is important to take a moment to reflect on your results. Are there any anomalies in your data? (This is often a reason to collect more data.) Are your final results and uncertainties reasonable? How do your results compare with your hypothesis?
At this point, you need to consider if your results are conclusive. Review the section Iterative Experimental Design above. If your results are inconclusive, then can you think of some reasonable* steps that you can take to improve your measurement? If so, then come up with a revised experimental plan and try it!
*Reasonable is subjective. We don’t expect for the purposes of our Module 1 that you will take hundreds of data points. But if taking 5 more data points will result in a stronger conclusion, then we encourage you to do so! It is also important to recognize that statistical analysis is not valid for very small numbers of data points. As a rough guide we would not consider a statistical analysis relying on less than 5 data points to be valid and therefore recommend you collect no fewer than 5 data points for each mass.
Next week you will make use of the Matlab software package to plot your data. If you do not have Matlab installed on your device we encourage you to install it to be prepared for next week’s assignment (HMC has a site license). If you have any issues please reach out to us. The CIS help desk can also be helpful with installation issues.
Checkpoint #3
Please submit the following to Checkpoint #3 on Gradescope
-
A screen-shot showing an organized spreadsheet used for data collection
-
A histogram for each mass tested showing the distribution of the number of data points collected as a function of the angle \(\theta_c\). You should have collected data for five different masses, with 5 data points for each mass.
-
The value you obtained for the coefficient of static friction, \(\mu_s\), for 3 of the 5 masses (smallest, middle, and largest), including the estimated uncertainty. Please make sure to use significant figures appropriately. If unsure please reread the section on significant figures, come to office hours to discuss, and/or consult your classmates through Piazza.
-
A single-sentence, preliminary conclusion that you can draw about the hypothesis based on your experimental data
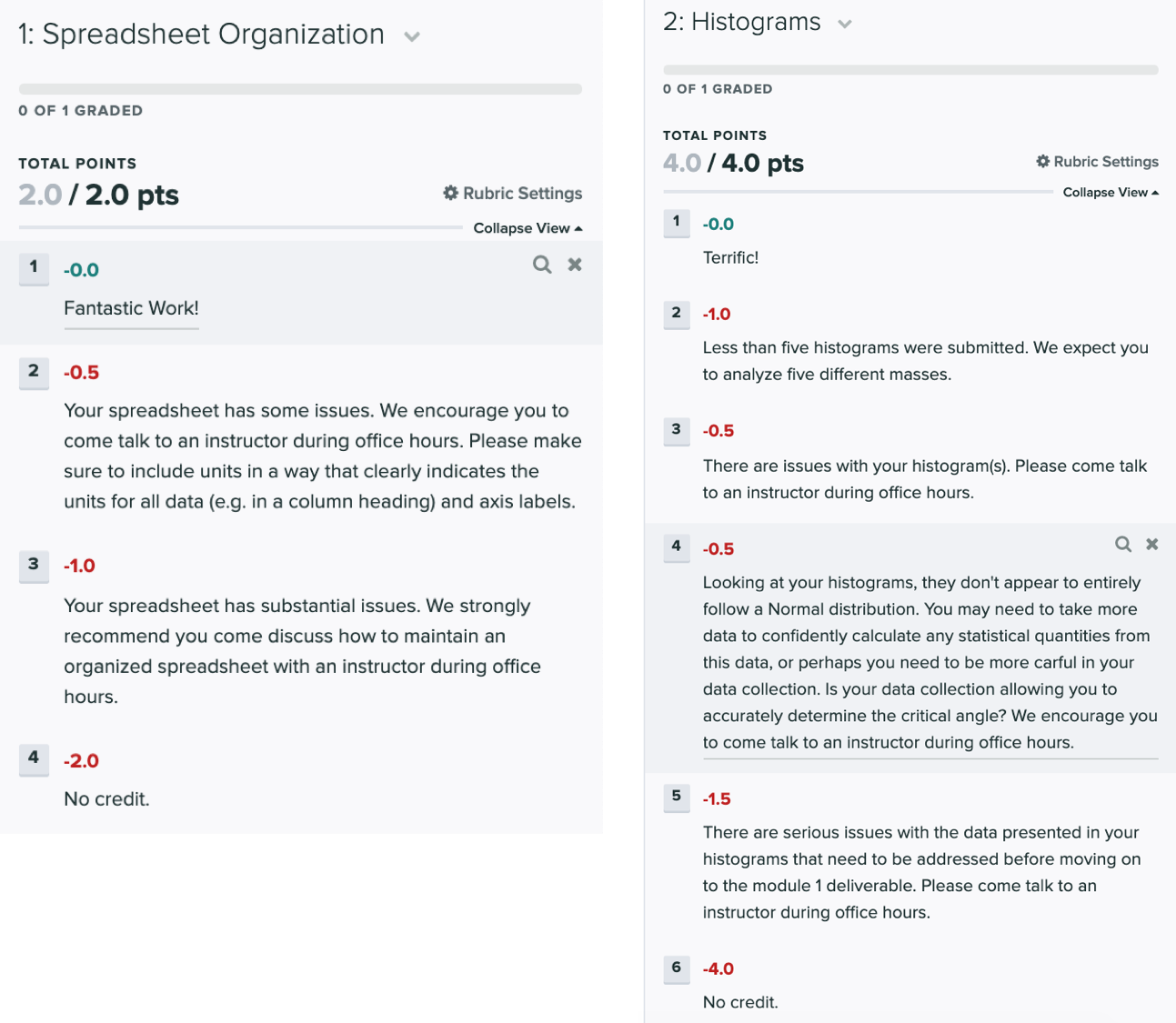
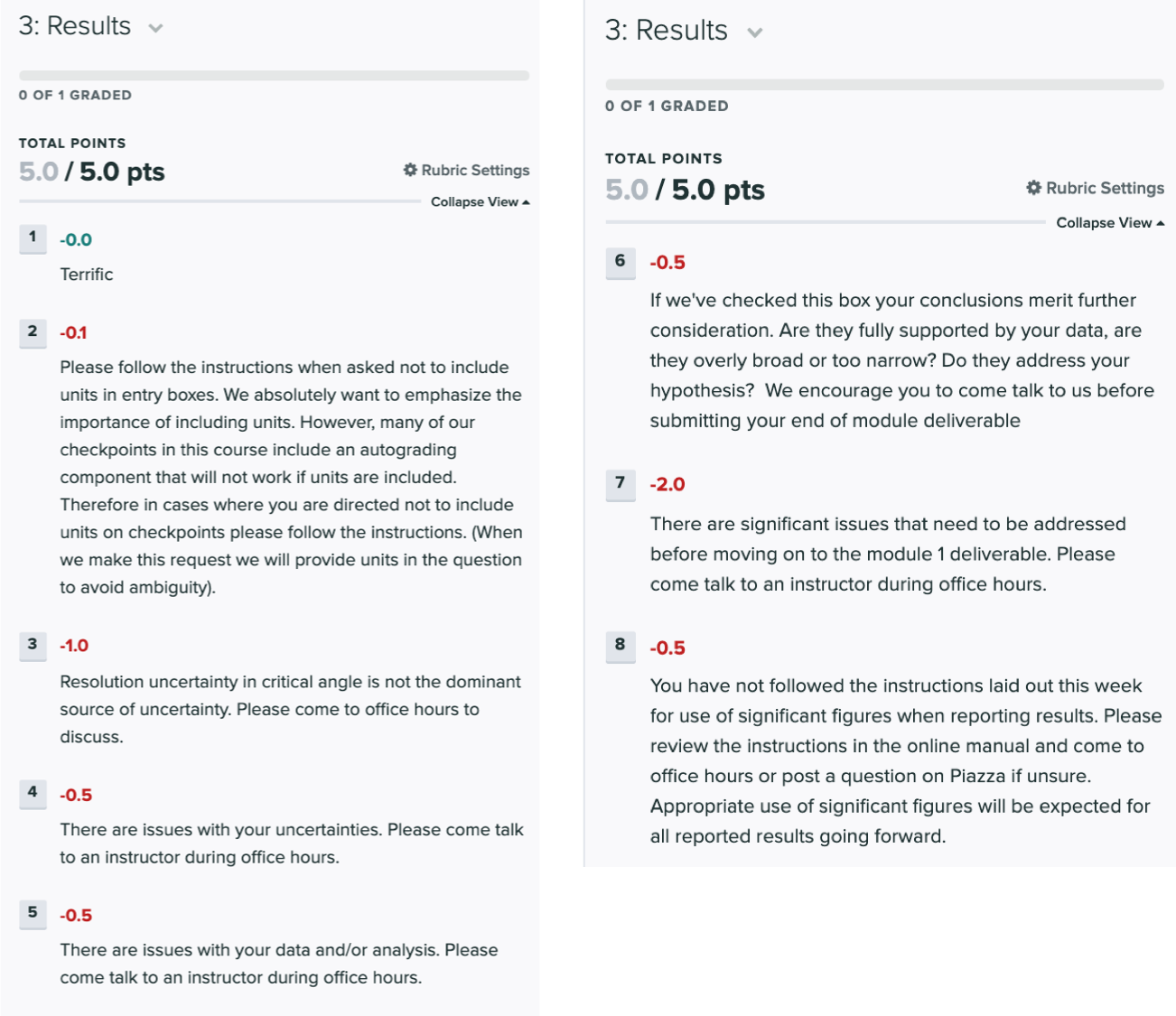
Grading Rubric
The tentative rubric that will be used to evaluate this deliverable is provided below. Please keep in mind that these rubric items are subject to change as we can never foresee all the issues that may arise. This is meant to give you a sense of how it will be graded.
Click on the below images to enlarge in a new tab:
Don’t forget to double check that you’ve completed all of this week’s miniquestions at this link.
When you’ve received feedback on your Week 3 checkpoint, get started on Week 4.